
شاید برای شما هم اتفاق افتاده باشد که یک سایت کالکشن شیرپوینت خودتان حجمش از مقدار استاندارد و Best Practice شیرپوینت بالاتر رفته باشد و یا اینکه از ابتدا می دانید این سایت قرار است برایش این اتفاق بیافتد. حال باید چه کرد؟
در این مقاله قصد داریم یکی از کارهایی که میتوان با آن performance دیتابیس را بالابرد به شما معرفی کنیم. در Case Study مورد نظر ما سایت کالکشنی در شیرپوینت داریم که حجم آن به یک ترابایت رسیده است. برای اینکه ما حال این سایت کالکشن و دیتابیس مورد نظر را بهتر کنیم باید مراحل زیر را انجام دهیم.
مراحل انجام کلی کار به صورت زیر است:
- ابتدا باید توی فایل گروپ Primary تعدادی دیتافایل خالی ایجاد کنیم.
- بهتر است که دیتا فایلهای ایجاد شده را در دیسک های مجزا قرار دهیم.
- تعداد این دیتا فایل ها باید کوچکتر یا مساوی تعداد Coreهای CPU باشد.
- حجم همه دیتافایل ها یکسان باشد.
- Trace Flag عه 1117 را باید فعال کنیم برای رشد همزمان همه دیتا فایل ها
- در مرحله بعد باید دیتا فایل حجیم اولیه را دیتاهاش را خرد کنیم توی دیتافایل های ایجاد شده
- بعد از عملیات Shirink File که انجام دادیم همه ایندکس های اون دیتابیس Fragment میشوند که باید ایندکس ها هم Rebuild شوند.
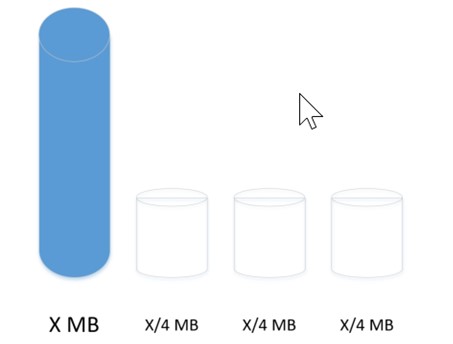
1- ابتدا باید توی فایل گروپ Primary تعداد مورد نظر دیتا فایل را با توجه به Cpu Core ها ایجاد کرد که در مثال ما فرض میکنیم که تعداد Cpu Core های ما 4 تاست و من 4 تا دیتافایل ایجاد میکنم که از همه ظرفیت CPU بتونم استفاده کنم و اون دیتا فایل حجیم 1ترابایتی را به 4 تا دیتا فایل با حجم مساوی تقسیم کنم.
برای ساخت دیتا فایل جدید باید دستور زیر را قرار داد:
ALTER DATABASE SPS_Content_Si_Portal_Financial_TEST ADD FILE ( NAME = 'SPS_Content_Si_Portal_Financial_TEST_DATA1', FILENAME = 'I:\SPS_Content_Si_Portal_Financial_TEST_DATA1.mdf',SIZE = 1GB , MAXSIZE = UNLIMITED, FILEGROWTH = 512MB ), ( NAME = 'SPS_Content_Si_Portal_Financial_TEST_DATA2', FILENAME ='I:\SPS_Content_Si_Portal_Financial_TEST_DATA2.mdf',SIZE = 1GB , MAXSIZE = UNLIMITED, FILEGROWTH = 512MB ), ( NAME = 'SPS_Content_Si_Portal_Financial_TEST_DATA3', FILENAME = 'I:\SPS_Content_Si_Portal_Financial_TEST_DATA3.mdf',SIZE = 1GB , MAXSIZE = UNLIMITED, FILEGROWTH = 512MB ), ( NAME = 'SPS_Content_Si_Portal_Financial_TEST_DATA4', FILENAME = 'I:\SPS_Content_Si_Portal_Financial_TEST_DATA4.mdf',SIZE = 1GB , MAXSIZE = UNLIMITED, FILEGROWTH = 512MB ) TO FILEGROUP [PRIMARY] GO
در اینجا باید به چند نکته توجه داشت. اول اینکه حجم همه دیتا فایل های یکسان باشد و از همه مهمتر اینکه FileGrowth عه همه دیتا فایل ها به صورت درصدی نباشد و همین عدد 512 مگابایت باشد و همینطور SIZE هم 1 گیگابایت باشد. اینکه FileGROWTH روی درصدی که به صورت دیفالت هست نباید باشد به این دلیل است که وقتی درصدی باشد مثلا 10 درصد ما هر گاه DataBase مان به حجم حداکثری میرسد یک Locking ایجاد میکنه تا بتونه رشد کنه که فقط به اندازه 10درصد رشد میکنه و این ممکن است در طول روزها انجام شود که از نظر پرفورمنسی دیتابیس را با مشکل مواجه کند.
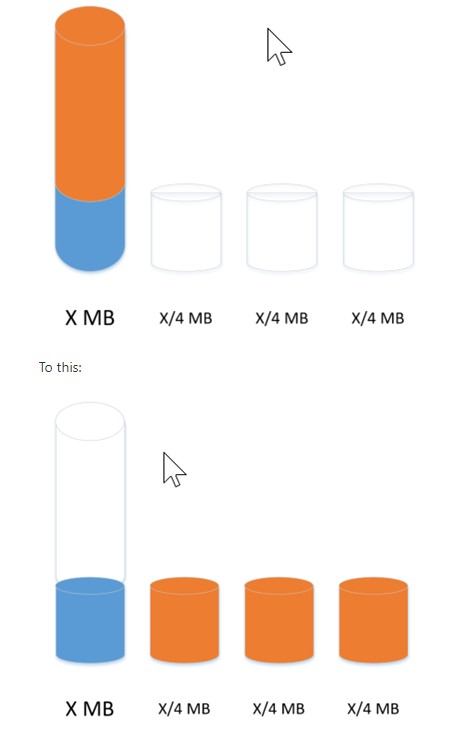
2- بعد از اینکه دیتا فایل ها را ایجاد کردیم نوبت به آن میرسد که آن دیتا فایل حجیم را توی دیتا فایل های ایجاد شده خرد کنیم که برای این کار باید از دستور ShrinkFile استفاده کنیم که دستور آنرا جلوتر برای شما قرار خواهم داد. فقط قبل از این کار باید TraceFlag عه 1117 را روی دیتابیس مورد نظر فعال کرد که این TraceFlag کاری که میکند باعث میشود دیتافایل ها به یک اندازه رشد کنند و یک دیتافایل بیش از حد رشد نکند زیرا اگر یک دیتافایل بیشتر از بقیه رشد کند بعد از آن هم بقیه دیتاها را بیشتر به سمت خودش میکشد و این باعث بوجود آمدن مشکلات پرفورمنسی در آینده خواهد شد.
با دستور زیر این عملیات انتقال محتویات به دیتافایل های دیگر به درستی انجام میگیرد. فقط درنظر داشته باشید این عملیات زمان بر میباشد. به این نکته هم باید دقت داشت در حین این کار باید حواستان به LogFile هم باشد چون بزرگ خواهد شد و باید یک فضای مناسب برای آن در نظر گرفت.
3- بعد از انجام موفقیت آمیز این کار ایندکس های آن دیتابیس Fragment می شوند که باید این مشکل را نیز حل کرد که با دستور زیر میتوان وضعیت Fragmentation ایندکس ها را مشاهده کرد.
SELECT dbschemas.[name] as 'Schema', dbtables.[name] as 'Table', dbindexes.[name] as 'Index', indexstats.avg_fragmentation_in_percent, indexstats.page_count FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id] INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id] INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id] AND indexstats.index_id = dbindexes.index_id WHERE indexstats.database_id = DB_ID() ORDER BY indexstats.avg_fragmentation_in_percent desc
برای رفع این مشکل هم کافیست تا کوئری زیر را اجرا کنید تا همه ایندکس های دیتا بیس مورد نظر Rebuild شوند.
DECLARE @TableName VARCHAR(255) DECLARE @sql NVARCHAR(500) DECLARE @fillfactor INT SET @fillfactor = 80 DECLARE TableCursor CURSOR FOR SELECT OBJECT_SCHEMA_NAME([object_id])+'.'+name AS TableName FROM sys.tables OPEN TableCursor FETCH NEXT FROM TableCursor INTO @TableName WHILE @@FETCH_STATUS = 0 BEGIN SET @sql = 'ALTER INDEX ALL ON ' + @TableName + ' REBUILD WITH (FILLFACTOR = ' + CONVERT(VARCHAR(3),@fillfactor) + ')' EXEC (@sql) FETCH NEXT FROM TableCursor INTO @TableName END CLOSE TableCursor DEALLOCATE TableCursor GO
البته برای Rebuild کردن ایندکس ها میتوانستیم از ابزار Maintenance Plan هم استفاده کرد که در سایت مایکروسافت این کار را به طور کامل انجام داده است.