
چیزی که اغلب برای نصب و راه اندازی high-availability SharePoint مورد نیاز است آن است که، در زمان خرابی و یا نیاز به maintenance یکی از فارمها که باعث offline بودن کامل آن می شود، فارم دوم در دسترس بوده و قطعی و یا خرابی فارم اول احساس نشود. به طوری کلی این مفهوم در خصوص کلیه سیستم ها که نیاز به high-availability دارند صادق است. به طور مثال در رابطه با SQL Server نیز مفاهیم مشابهی وجود دارد که در مقاله دیگری با عنوان آموزش SQL Server Always On آورده شده است.
منبع: بلاگ مایکروسافت
نکته: در صورتی که تمایل دارید در خصوص Disaster-Recovery/Hot-Standby در فارمهای شیرپوینت بیشتر مطالعه کنید اینجـــــــــا را کلیک کنید.
این مفهوم چندان پیچیده به نظر نمی رسد ولی پیاده سازی آن در SharePoint کار ساده ای نیست. طبیعتا هزینه های پیاده سازی این طرح ها نیز ارزان نیستند. ولی برای کارها و مواردی که بالابودن سرورها و فارم های اطلاعاتی بسیار مهم بوده و درجه اهمیت بالایی دارد، اولین و بهترین راه آن است که single point of failure را از مهمترین فارم SharePoint خود حذف کنیم. بدین معنا که تنها یک سرور که single point of failure است نداشته باشیم.
بروزرسانی: قابلیت DR یا Disaster-Recovery در SharePoint با استفاده از SQL Server Always On بسیار شگفت انگیز تر شده است. در خصوص نحوه تنظیم و استفاده از آن در مقاله ای دیگر توضیح داده خواهد شد.
در این دستورالعمل من یک دیتاسنتر ثانویه به عنوان mirror ایجاد کرده ام و می خواهیم ببینیم که زمانی که farm اول offline می شود چطور کاربر از farm دوم سرویس خود را دریافت می کند. از کار افتادن farm در SharePoint دلایل مختلفی می تواند داشته باشد که می توانند جزو دسته بندی کلی تر عمدی و تصادفی باشند. در هرصورت صورت مسئله کاملا واضح است: online نگاه داشتن SharePoint Applications با هر هزینه ای.
برای تست می خواهیم فرض کنیم که farmی در شیرپوینت داریم و می خواهیم روی آن تنظیمات hot-standby را پیاده سازی کنیم که به هردلیلی ممکن است offline شود (اشاره: موارد بسیاری می تواند وجود داشته باشد). هدف بسیار ساده است، زمانی که فارم اول دچار مشکل شد بلافاصله فارم دوم شروع به سرویس دهی به کاربر نماید و همچنین نمی خواهیم کاربر متوجه مشکل ما شود. تنظیم نهایی ما چیی مشابه به تصویر زیر خواهد بود:
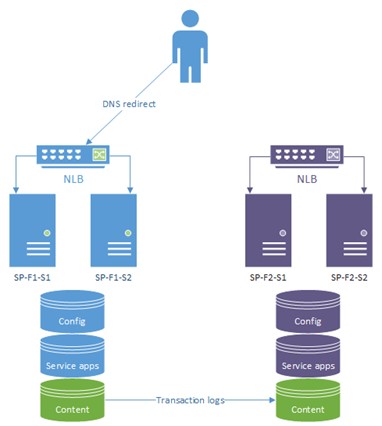
آموزش high-availability SharePoint
دراین طراحی همه چیز در سمت راست تصویر فوق قرار گرفته است. وقتی که دیتاسنتر سمت راست به هر دلیلی offline شود کافی است کاربران را به سمت دیتاسنتر سمت چک ریدایرکت کنیم تا زمانی که دیتاسنتر اول مجددا ریکاور گردد. برای رسیدن به این مقصود نیاز به سناریویی شفاف داریم که خروجی پیاده سازی آن به صورت زیر خواهد بود:
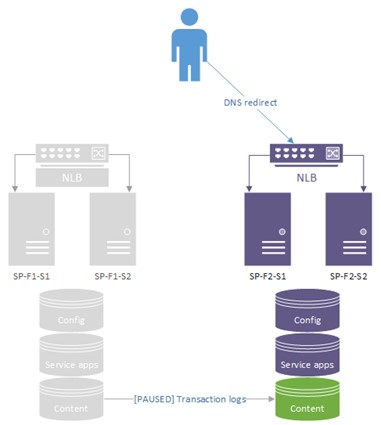
ایجاد فارم شیرپوینت Hot-Standby/Disaster Recovery
به صورت خلاصه ما آن را DR Farm می گوییم. راه اندازی فارم ثانویه شامل موارد زیر است:
- راه اندازی فارم دوم با configuration DB خود و Search app و غیره. فعلا بدون هیچ web-application.
- فعال سازی log shipping بر روی content DB.
- هنگامی که content DB بر روی فارم دوم پشتیبانی می شود می توانید app های مورد نیاز خود را اضافه و تنظیم نمائید (content DB جدید ایجاد نکنید).
- در نهایت در هنگام رخ دادن failover، تصمیم بگیرید که چه کاری می خواهید انجام دهید. گزینه ها عبارتند از: حالت فقط خواندنی تا زمانی که فارم 1 دوباره زنده شود(ساده ترین) و یا فارم 2 کاملا خواندنی/نوشتنی شود که در این صورت می بایست مهاجرت محتوای تغییرات به فارم اولیه مجددا انجام شود.
آماده سازی فارم ثانویه:
از آنجا که می خواهیم فارم دوم در هر زمانی که فارم اول از کار افتاد بتواند سرویس مورد نظر را ارائه دهد، فارم دوم می بایست کاملا مستقل بوده و تنظیمات مورد نیاز بر روی آن انجام شده باشد. نکته اصلی این تمرین آن است که ما می توانیم کلیه کاربران را به سمت فارم دوم هدایت کنیم ولی به صورت معجزه آسایی فارم دوم کاملا بروز بوده و کلیه اطلاعات فارم اول را شامل می شود و نتیجه در صورت نیاز فارم اول می تواند کاملا از دسترس خارج شود. خرابی ها و یا همان failovers قابل پیشبینی نیستند، نتیجتا برای رسیدن به high-availability در شیرپوینت نیاز همه سرویس ها به صورت محلی داریم(2 x of everything locally). یعنی AD, Sql و SharePoint زیرا از کار افتادن هریک از آنها فارم اصلی را از کار خواهد انداخت.
نصب و تنظیم شیرپوینت
در این مثال فرض این است که در شیرپوینت یک فارم وب به طور کامل در حال اجرا است. گام اول نصب شیرپوینت است و این که مطمئن شویم که همان SharePoint Patch-Level فارم اول را داراست. اگر می خواهید از عملکرد صحیح fail-over خود مطمئن شوید، دقت کنید که SharePoint Patch-Level هر دو فارم یکسان است.
فعال سازی Log Shipping از Sql Server اصلی به Sql Server ثانویه
برای پیاده سازی log-shipping 3 مرحله مورد نیاز است که هر 3 مرحله نیاز به تنظیم دارند:
- Backup
- کپی کردن transaction log در محل بکاپ
- Copy
- کپی کردن فایل از سرور 1 به سرور 2. این کار می تواند با استفاده از سرویس DFS به صورت خودکار انجام شود
- Restore
- اعمال کردن فایل کپی شده بر روی سرور ثانویه
- Pause & repeat
هر 15 دقیقه می بایست این مراحل تکرار شوند
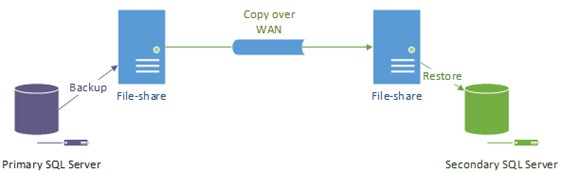
آموزش high-availability SharePoint
در تصویر فوق، خطوط بنفش به وسیله Sql اصلی انجام می شود و خطوط سبز به وسیله Sql ثانویه. برای رسیدن به اهداف این آزمون ما دو فضای اشتراکی در نظر گرفته ایم، اما دنیای واقعی ممکن است این فرایند به خوبی کار نکند به طور مثال اگر دو مرکز داده در کشورهای مختلف باشند.
کل این فرایند می بایست که در ابتدا تنظیم گردد و همچنین بدیهی است که یک کپی از بانک اطلاعاتی می بایست در سرور دوم و آماده به کار قرار گیرد.SQL Server Management Studio به شما این امکان را می دهد که در صورت نیاز دیتابیس محتوا را به صورت خودکار راه اندازی کنید، بدین معنا که می تواند یک نسخه پشتیبان کامل از پایگاه داده محتوا تهیه کرده و آن را به محل دیگری بر روی سرور 2 کپی کند و آماده برای شروع فرایند log-shipping باشد.
در مثال ما SQL-SP2013\SP15 اینستنس اصلی Sql ماست که content DB در آن به صورت read/write تنظیم شده است. Sql دوم یا ثانویه SP2013\SP15B است که به صورت فقط خواندنی است که configuration DB، service applications و … خود را دارد.
خوب در اولین قدم می بایست content DB را که می خواهید log-shipping را برای آن فعال کنید از ssms انتخاب کنید و ادامه راه…

روی گزینه back-up کلیک کنید تا بتوانید تنظیمات مربوط به تهیه نسخه پشتیبان از transaction-log را ادامه دهید. طبیعتا می بایست محل قرارگیری فایل بکاپ را مشخص کنید.

این job آخرین اطلاعات transaction-log را در مسیر file-share قرار می دهد. احتمالا شما نیازی به تغییر مقادیر پیشفرض ندارید.
حال می بایست instanceی که می بایست دیتا روی آن بارگزاری شود را انتخاب کنیم. باید یک کپی از پایگاه داده های content بر روی سرور دوم وجود داشته باشد و با توجه کنید که هنوز هیچ web application در فارم دوم ایجاد نکرده ایم و content DB در SQL ایجاد نکرده ایم. برای این تست می خواهیم کار سخت restore کردن بر روی سرور دوم را به دوش Sql Server بگزاریم. پس از اتصال به SQL Server دوم، گزینه “generate a full backup and restore it onto the secondary” را انتخاب کنید.

در اینجا می بایست SQL دوم متصل شوید. همچنین می خواهیم SQL Server ایجاد content DB دوم را نیز آغاز کند. توجه کنید که همچنان نباید اثری از WSS_Content در Sql ثانویه باشد. اگر وجود دارد پروژه fail خواهد شد.
خوب در ادامه بر روی Copy Files کلیک کنید. این قسمت برای تنظیم کردن محل کپی شدن transaction log است.
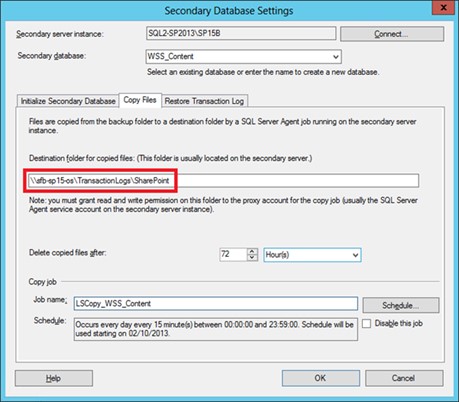
این یکی از jobهای Sql Server ثانویه است تا بتوانیم فایل ها را از محلی که بکاپ گرفته شده است به محل مورد نظر خود انتقال دهیم. البته در صورتی که از سیستم انتقال فایل از یک نقطه به یک نقطه remote استفاده می کنید، تنظیم این موارد ضروری نیست. در مثال ما source/destination یکسان است بنابراین برای ساده شدن مثال از این مرحله گذر می کنیم.

و در انتها job مربوط به transaction-log restore. دقت کنید که این تنظیمات را به حالت پیش فرض رها نکنید.
تنظیمات و پیکربندی های مهم SharePoint
در درجه نخست اطمینان حاصل کنید که حالت standby را restore کردن فعال کرده باشید و یا فارم ثانویه تا زمانی که به صورت دستی به صورت قابل استفاده restore شود قابلیت و یا دسترسی خواندن نداشته باشد. زمانی که transaction-log ورودی باشد ما می توانیم از آن به صورت read-only استفاده کنیم به شرطی که حال standby mode را انتخاب کرده باشیم. این قابلیت اجازه می دهد که شیرپوینت از حداقل امکانات پایگاه داده ها استفاده کند حتی اگر قابلیت نوشتن نداشته باشد.
همچنین گزینه “disconnect users” در زمان restore بسیار مهم است. به این دلیل که می خواهیم restore در بالاترین سطح کار کند. در صورتی که در زمان restore شیرپوینت کانکشن بازی داشته باشد عملیات restore با شکست مواجه خواهد شد مگر گزینه فوق را انتخاب کرده باشیم. شاید در نگاه اول این اتفاق چندان بد نباشد ولی باید در نظر بگیریم که در صورتی که در مدتی طولانی عملیات restore اتفاق نیفتد، با حذف بکاپ های transaction-log توسط backup clean-up زنجیره transaction-log قطع می شود و تنها راه حل مشکل استفاده از full backup & restore خواهد بود. گاها با توجه به حجم بانک اطلاعاتی این اتفاق خود به یک مشکل پیچیده تبدیل می شود. نتیجتا بدون در نظر گرفتن این که چه اتفاقی ممکن است رخ دهد از restore شدن transaction-log مطمئن شوید.
جهت اطلاع حتما می دانید که در صورتی که SharePoint بخواهد به DB دسترسی پیدا کند و به دلیل restore با خطا مواجه شود، شما با event شماره 3760 (login isn’t setup correctly) مواجه می شوید. که البته در این وضعیت Sql بانک اطلاعاتی با به وضعیت “single-user” برده و نتیجتا به غیر از connectionی که در حال بازیابی یا restore است سایر درخواست ها deny خواهند شد.
به پایان رساندن تنظیمات log-shipping
با فشردن کلید ok مراحل زیر می بایست اجرا شود:

آنچه که در حقیقت در حال رخ دادن است اجرا شدن 2 اسکریپت است، یکی از Sql ها تعداد 3 عدد job با محوریت back-up, copy و restore ایجاد می کند.

همانطور که در تصویر بالا قابل مشاهده است شما jobهای مربوط به transaction log shipping را می بینید و همچنین در تصویر زیر وضعیت صحیح content DB:

بانک اطلاعاتی بر روی سرور ثانویه ایجاد شده است ولی در وضعیت read-only است.
Mount کردن دیتا بیس بانک اطلاعاتی کپی
حال که content DB داریم می توانیم SharePoint application ها را برای استفاده ایجاد کنیم ولی نیاز به اضافه کردن applicationها بدون پایگاه داده داریم زیرا می خواهیم content DB که sync است را بعد از ایجاد application ها داشته باشیم و نتیجتا زمانی که فقط از نام پایگاه داده sync در تعریف application جدید استفاده می کنیم با مجموعه ای از خطاها در search app مواجه مبنی بر این که پایگاه داده فقط خواندنی است روبرو خواهیم شد. بنابراین یک برنامه جدید ایجاد می کنیم که نام پایگاه داده موقت دارد سپس آن را حذف کنید و یا با استفاده از PowerShell می توانید یک برنامه بدون نیاز به content DB ایجاد کنید، سپس پایگاه داده محتوا را با Mount-SPContentDatabase یا از طریق مدیریت مرکزی اضافه کنید.
پس ایجاد برنامه و باز کردن آن در وب البته با content DB فقط خواندنی و چیزی شبیه به این خواهید دید:

تا زمانی که log-shipping را متوقف نکرده این DB در حالت فقط خواندنی باقی خواهد ماند.
Failing Over در دنیای واقعی، واقعا منفجر شد!
هنگامی که مرکز اطلاعات و یا همان Data Center اصلی شما از کار می افتد، مطمئنا اصلی ترین سوال این است که «آیا ما انتظار داریم که فارم اصلی به زودی آنلاین شود؟». البته که ما می توانیم دسترسی به خواندن و نوشتن را روی پایگاه داده ثانوی فعال کنیم، اما در صورتی که بخواهیم کاربران مجددا از آن فارم استفاده کنند باید این تغییرات را به SQL Server اولیه برگردانیم، که می تواند بسیار پر زحمت باشد. برای بعضی از خرابی ها کافی است فقط یک کپی فقط خواندنی داشته باشید تا مشکل با فارم اولیه حل شود و log-shipping ادامه پیدا کند. به این ترتیب نیاز به هیچ تغییری به روی فارم ابتدایی نیست.
به عنوان بخشی از failover یا همان خرابی، شما باید تصمیم بگیرید که آیا قصد دارید نوشتن اتفاق بیوفتد، تا پیش از آن همه چیز فقط خواندنی است.
چگونگی انجام فرایند استفاده از Disaster Recovery Farm
گرفتن آخرین log-data:
اولین چیزی که می بایست انجام دهید حصول اطمینان از این نکته مهم است که آیا اطلاعات ثانویه شما دارای آخرین تغییرات ممکن است؟ که از طریق restore کردن آخرین transaction-log این اطمینان حاصل خواهد شد. همچنین باید تا حدودی منطقی فکر کنید که آیا Sql اولیه می توانید log بیشتری نیز تولید کند؟ اگر نه، آیا آخرین transaction-log ایجاد شده کدام است؟ آیا به فایل سرور دوم و یا در پوشه اشتراک گذاری سرور دوم کپی شده؟ و …. نکته این است که شما باید فایل نهایی را پیدا کنید و بر روی Sql ثانویه restore کنید، البته اگر می خواهید مطمئن شوید که فارم ثانویه شما دارای آخرین محتوا است. این معمولا یک مشکل بزرگ است، اما همه فایل های TRN ممکن را فراهم کرده و restore کنید.

در اینجا ما آخرین فایلهای TRN موجود در به محل backup انتقال دادیم تا بتوانیم بر روی DB ثانویه restore کنیم. اگر می توانستید از transaction-log نسخه پشتیبان جدیدی تهیه کنید پس حتما انجام دهید. دقت کنید که در هنگاه بازیابی اطلاعات فقط کافی است آخرین فایل پشتیبان را انتخاب کنید. سرور جهت تشخیص نسخه های قبلی به اندازه کافی هوشمند است.

در مثال خوب ترتیب LSN ها به خوبی دیده می شود.
انتقال ترافیک به فارم ثانویه:
در ادامه و جهت انتقال کاربران به فارم Disaster-Recover یا همان فارم ثانویه می بایست DNS خود را مجددا تنظیم کنید. به طور مثال اگر سایت ما به آدرس 10.0.0.1 اشاره می کند کافی است با تغییر DNS کاری کنیم که به آدرس 10.0.1.1 اشاره کند. این یک اتفاق جادویی نیست و تنها با تغییر رکورد A در DNS به سادگی امکان پذیر است. به مدت زمان مورد نیاز جهت انتشار DNS توجه داشته باشید.
یکی دیگر از موارد آن است که یک نام متفاوت برای فارم ثانویه داشته باشید. مثلا ReadOnly.Site.com و با داشتن یک reverse-proxy (برای مثال TMG Server) همه درخواست ها را به نام دوم و با استفاده از HTTP 302 منتقل یا redirect می کنیم.
متوقف کردن log-shipping:
در صورت امکان هر دو job مربوط به log-shipping را متوقف کنید. همانطور که دیدید این job ها در هر یک از Sql ها بودند و شما می توانید با استفاده از ssms آنها را متوقف کنید. کافی است پایگاه داده منبع را پیدا کرده و با غیرفعال کردن گزینه “Enable log-shipping” که دقیقا مخالف آنچه که در تنظیم آن گفته بودیم است آن را غیرفعال کنید.
فعال سازی حالت Read/Write برای کاربر:
زمانی که تصمیم گرفتید که کلیه وظایف توسط فارم ثانویه انجام پذیرد می بایست content DB را نوشتنی کنید. برای انجام این کار می توانید به سادگی از دستور زیر استفاده کنید:
ALTER DATABASE [WSS_Content] SET READ_WRITE WITH NO_WAIT
GO
کارهای دیگری که می بایست بر روی failover انجام دهیم
به استثنای اینکه شما اسکریپت دقیقی داشته باشید که زمانی را که فارم وب شما 100٪ از دسترس خارج شده است را تشخیص دهد، در سایر موارد می بایست این کارها را به صورت دستی انجام دهید. با توجه به این که پیاده سازی فرایندهای ذکر شده چندان هم ساده نیست، و همچنین خودکار نیست، اما نکته مهم این است که وقتی فارم تولید ما به دلیل ناشناخته ای از کار بیوفتد و روسای شما با استفاده از تلفن به طرف شما حجوم بیاورند، مطمئنم خوشحال خواهید شد اگر DR Farm را راه اندازی کرده باشید؛ برای پوشش دادن مدت زمانی که بتوانید بفهمید که چه اتفاقی بر روی فارم اصلی افتاده است.
برای عملیاتی کردن فارم standby خود مراحل زیر را انجام دهید:
- فارم را برای عملیات آماده کنید
- Sql Server Agent را غیرفعال کنید
- Dismount/mount کردن content DB برای بروزرسانی مجدد تعداد site-collation ها. تا زمانی که پایگاه داده mount باشد هر site-collaction جدیدی که به سایت اضافه شده باشد در ثانویه دیده نمی شود مگر زمانی که شما dismount و remount content DB را انجام دهید.
- تصمیم بگیرید که آیا میخواهیم اجازه خواندن و نوشتن در فارم ثانویه را داشته باشیم، که اساسا شامل نیاز به انجام Full Backup به Sql فارم اولیه خواهد بود، البته در صورتی که ما بخواهیم آن را مجددا به عنوان فارم اصلی احیا کنیم.
اتفاقات بدی که می تواند بر روی failover رخ دهد
با توجه به اینکه ما محیط بسیار پیچیده ای را در دو مکان کاملا متمایز mirror می کنیم، اشکالات زیادی می تواند رخ دهد. منظور از اشتباه و یا اشکال آن است که پس از failover، ارائه خدمات نرمال به دلیل مشکلاتی امکان پذیر نباشد. امکان دارد برخی از مشکلات به اندازه شدید باشند که کل برنامه از کار بیوفتد، که در این صورت data center ثانویه شما چیزی جز یک آزمایش گرانقیمت به نظر نمی رسد؛ اشکالات دیگر می تواند به معنای رفتار غیر منتظره سیستم باشد، مثلا چیزی را جستجو کنیم و نتیجه ای دریافت نکنیم.
در هرصورت اگر دقت نکنید به طور کلی در هنگام failover دو دسته خطا ممکن است رخ دهد:
اتفاقات بسیار بد
- SharePoint Patch Level که اگر این کار درست انجام نشده باشد، انتظار اتفاقات وحشتناکی را داشته باشید. شیرپوینت binaries تنها با شیوه خاصی از پایگاه داده شیرپوینت کار می کند – اگر failover شما زمانی رخ دهد که از نسخه 15.0.6060.5000 به یک نسخه از شیرپوینت قدیمی تر اتفاق بیوفتد، موفق نخواهید بود.
- راه حل های سفارشی که نیاز دارند با دقت مورد توجه قرار گیرند.
- تغییرات config دستی که به دلایل نیاز برنامه ها انجام شده اند اما SPWebConfigModification نیست (به همین دلیل به طور خودکار اعمال نمی شود).
اتفاقات نه چندان بد
- مسیرهای مدیریت شده یا همان managed path. اطمینان حاصل کنید که آنها بین فارم ها یکسان هستند.
- تنظیمات service application
- Performance بدین معنی که آیا DR Farm می تواند همان ترافیک فارم اولیه را مدیریت کند؟ که بسته به چگونگی آن می تواند یک مشکل “خیلی بد” باشد.
امیدوارم این مقاله کاربردی بوده و بتواند شما را در زمان رخ دادن مشکلات پیش بینی نشده کمک کند.
با سلام و احترام،
مطالبي که زحمت کشيديد و در اختيار گذاشتيد بسيار مفيد واقع شدند اما اشکال بنده اين است که من با شيرپوينت 2010 کار مي کنم و دو تا سرور دارم يکي اصلي و يکي پشتيبان وقتي سرور پشتيبان از دسترس خارج ميشه متاسفانه تارگت اودينس پورتالهام ميپره و بايستي همه web port هايي که تارگت دارند و پنهان کنم مشکل چيه راه حلي هست که ديگه با همچين مشکلي مواجه نشم ممنون ميشم راهنماييم کنيد.